분산 환경에서 Auto increment
보통 그냥 auto_increments 로 1->2->3->->9999 이런식으로 ID(pk)를 만드는 경우가 많다. 하지만 이는 분산환경에서 좋지 않다.
왜 그럴까?
데이터베이스를 수평확장을 하면 데이터베이스가 2개 이상이 될 텐데. 2개의 멀티 마스터 데이터베이스에서 1, 2, 3, 가 각각 생긴다면 서로 다른 데이터임에도 ID가 중복되기 때문에 같은 ID로 쿼리해도 매번 같은 데이터 반환을 보장 못할 수 있다.
그래서 보통은 1씩 증가 하게 하는 것이 아니라 데이터베이스 개수에 따라 증가 수를 다르게 한다.
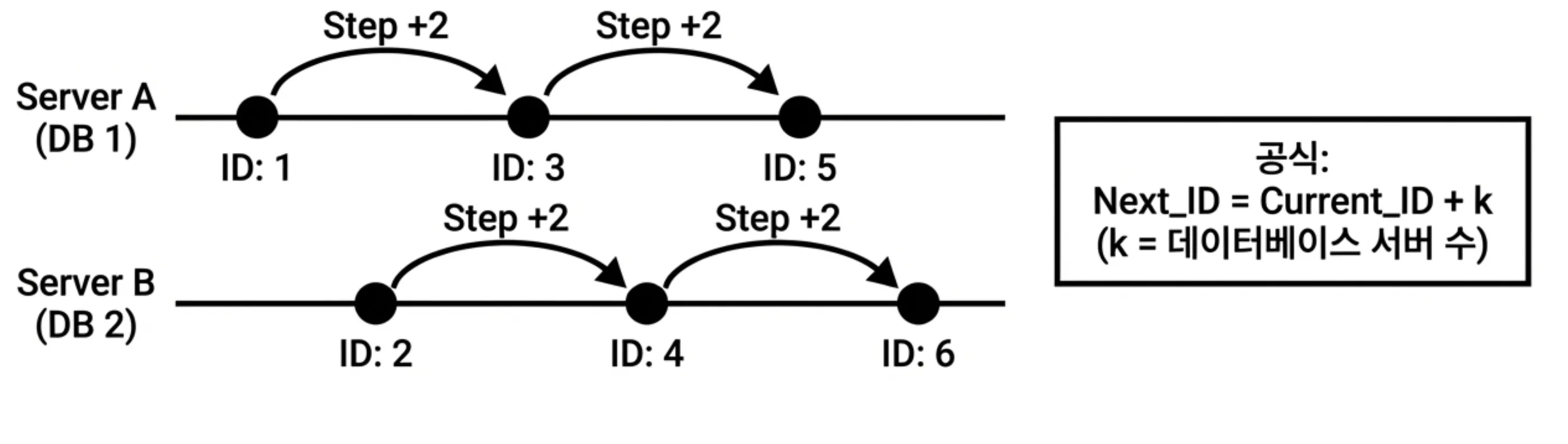
단점:
- 확장성에 약함: 데이터베이스 증가하면 증가폭 수정을 해도 끼워맞추기 어려움
UUID
우리의 믿고 쓰고 다시 쓰는 UUID! 과연 UUID는 어떨까
UUID는 128bit로 구성되어 있으며, 각각 서버에 독립적이게 동작한다.
wikipedia 에 따르면 “after generating 1 billion UUIDs every second for approximately 100 years would the probability of creating a single duplicate reach 50%”1 라고 한다. 즉 충돌되기 확률적으로 참 어렵다.
단점:
- 128bit로 구성되어 있어 auto increment보다 저장공간을 많이 차지한다.
- 정렬이 어렵다.
Ticket Server
Flickered 개발자 형님들은 그냥 ID 생성 서버를 따로 만들었다고 한다.2
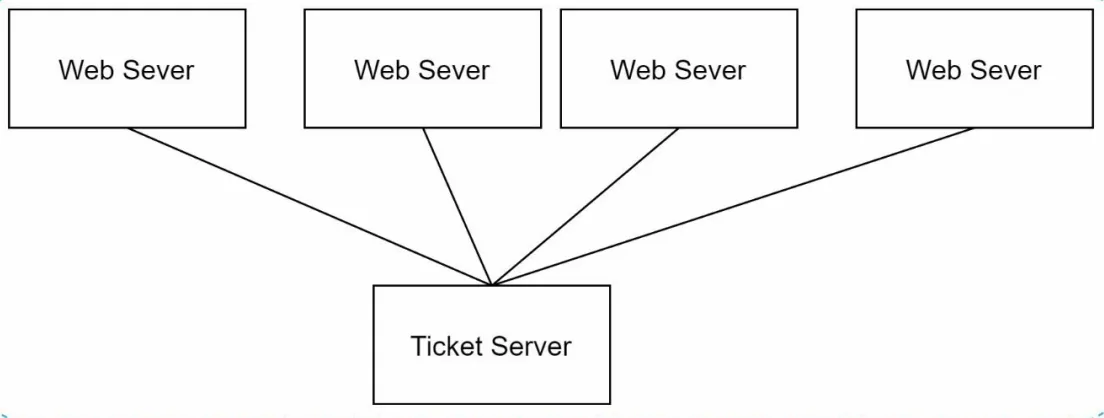
아티클을 읽어보면 AWS의 Dynamo 나 GUID(UUID의 한 종류)를 사용하지 않고도 가장 Dumbest한 방법으로 문제를 해결할 예시이다. 이 마인드는 Try Coding, Dear Boy! 에서 영감을 얻었다고 한다.
SPOF
아티클에서 Single Point of Failure(SPOF)를 해결하기 위해 2개의 Ticket Server를 사용한다고 기술한다. 한개는 짝수만 반환하고 다른 한개는 홀수만 반환한다.
Twitter snowflake approach

- sign bit: 1bit, 항상 0 하지만 미래에 사용될지 몰라서 남겨두는 것..
- timestamp: 41bit, 2^41 ms = 69년, 기준을 정해서 그 이후동안의 시간 측정
- datacenter id: 5bit, 2^5 = 32개의 데이터센터
- machine id: 5bit, 2^5 = 32개의 머신 per 데이터센터
- sequence number: 12bit, 2^12 = 4096개의 ID를 생성할 수 있다. 0-4095 까지 값을 가지고 매 millisecond 마다 0으로 초기화 된다.
Timestamp
Step:
- Timestamp의 값 -> 10진수
- add Epoch(기준 시간)
- convert millisecond to UTC time
- 최종: Apr 09 2026 16:51:31UTC
2^41 ms / 1000 sec / 60 min / 60 hour / 24 day / 365 year = 69.7 year
즉 69년 동안 사용할 수 있는 시간이다.
Sequence number
2^12 = 4096개의 ID를 생성할 수 있다. 0-4095 까지 값을 가지고 매 millisecond 마다 0으로 초기화 된다.
이걸로 만족하나?
책에서는 결국 64bit로 구성된 ID를 요구했기에 Snowflake approach가 가장 적합한 방법이라고 한다. 하지만 69년 뒤에는? 이 ID 방식이 유효할까? 라는 생각에 더 리서치를 해본다.
Snowflake를 넘어
Era bit
기존의 Snowflake는 69년 뒤에 ID 생성이 불가능하다. 이를 해결하기 위해 Era bit을 추가한다. 제일 앞에있는 signal bit를 era bit으로 사용한다. 0이면 1세대, 1이면 2세대… 이런식으로 이렇게 하게 되면 69년 * 2 = 138년 동안 사용할 수 있다.
Sonyflake
snowflake를 계량한 것이다. 기존에 timestamp를 41bit로 구성한 것을 39bit로 줄이고 machine id를 16bit로(기존 5bit datacenter + 5bit machine) 늘렸다. sequence number는 8bit로 기존보다 4bit 줄인다.
snowflake는 timestamp가 1ms 단위이지만 sonyflake는 10ms 단위이다.
그래서 sonyflake는 2^31 * 10 ms / 1000 sec / 60 min / 60 hour / 24 day / 365 year = 약 139년 동안 사용할 수 있다.
공식 github: https://github.com/sony/sonyflake
UUIDv7
128bit로 구성되어 있다. 책에서 요구하는 64bit는 아니지만 시간에따라 정렬할 수 있는 것도 중요 요구사항 중 하나 였기에 넣어봤다.
위에서 언급한 UUID는 UUIDv4로 랜덤한 값이라 시간에따라 정렬할 수 없다. 하지만 UUIDv7은 UUIDv1 처럼 시간에 기반해서 값이 만들어지므로 정렬이 가능하다.
기존 v1 은 사용자의 MAC address를 사용하기에 프라이버시 이슈가 있었지만 v7은 MAC address를 사용하지 않는다.
RFC 96523에서 볼 수 있다.
정확한 128bit 구조
+-----------------------+------+--------------------+------+-------------------------------+
| 48 bit | 4bit | 12 bit | 2bit | 62 bit |
+-----------------------+------+--------------------+------+-------------------------------+
| unix_ts_ms |ver(7)| rand_a (counter) |va(10)| rand_b (random) |
+-----------------------+------+--------------------+------+-------------------------------+
- 48bit timestamp: Unix Epoch 밀리초 단위 (실질 수백 년 사용 가능)
- 12bit counter: 같은 밀리초 내에서 순서 보장 (monotonic)
- 62bit random: 충돌 확률 극소 + 예측 불가능
- Version 7, Variant 10 고정
결론
과연 당신의 서비스가 10년이라도 갈까? 10년 가면 당신은 이미 엑싯하고 개발을 다시는 안해도 될 것 같다.
그냥 이런게 있구나 하면서 꺼드럭 거리면 된다. 알고있으면 좋겠다~
Footnotes
March 23, 2026